- Nested Loop
- Merge
- Hash Joins.
These types are not directly exposed to us, but we can use them as a query hint. These are also known as physical joins in SQL Server. So let's discuss it in detail.
In AdventureWorks2012 Database, below is an example query
/********************************************/
SELECT
e.[BusinessEntityID] ,p.[Title]
,p.[FirstName] ,p.[MiddleName]
,p.[LastName] ,p.[Suffix] ,e.[JobTitle]
FROM
[HumanResources].[Employee] e
INNER JOIN
[Person].[Person] p
ON
p.[BusinessEntityID] = e.[BusinessEntityID]
/********************************************/
While executing the SQL server will create an appropriate plan for the query, execute it, and return the result set to the caller. SQL Server has multiple components to perform this series of tasks including query parsing, creating a query tree, creating a binary plan, and after all executing the query and returning the result set.
The actual execution of the query is handled by the storage engine component of the SQL Server. SQL Server uses a cost-based optimization technique for query plan creation. And it selects the most efficient "Good enough plan" for the given query.
To execute the above query SQL can select any one of joins, based on some criteria like.;
1. Size of table
2. Order of index used to join
3. Indexes available
4. Type of index – Clustered or Non-clustered
5. etc
Loop Join:
- SQL Server chooses Loop to join when one input set is small and the other one is fairly large and indexed on its join column.
- Nested loop join is the fastest join operation because they require least I/O and the fewest comparison. It's also called as nested iteration.
- It is particularly effective if the outer input is small and the inner input is pre-indexed and large.
- For many small transactions with small data set nested loop type of join is superior to merge and hash joins.
How it works?
- The nested loops join, uses one join input as the outer input table and one as the inner input table.
- The outer loop consumes the outer input table row by row.
- The inner loop, executed for each outer row, searches for matching rows in the inner input table.
- If there is an index being used in the query this join is called as index nested loop join
- If there is no index to be used in the query this join is called naive nested loop join.
- If the index is built as part of the query plan and destroyed upon completion of the query; it is called a temporary index nested loop join.

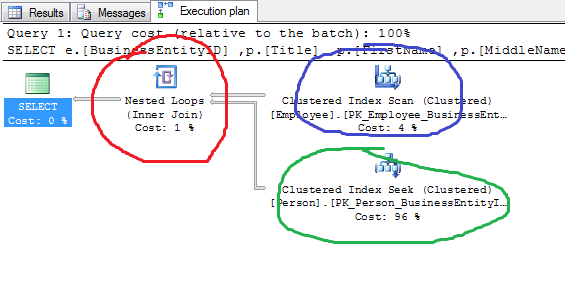
Nested Loop Join
In the above picture; the type of join which is the Nested loop is pointed with a red circle, the outer input table is with the blue circle and the inner input table is with the green circle.
Merge Join:
- If two inputs are not small but sorted on the join columns.
- A merger join is the fastest operation.
- It requires both tables to be sorted on the merged column.
How it works:
- When both inputs are sorted, this operator gets a row from each input and compares them.
- The rows are returned if they are equal (inner join).
- If they are not equal, the lower-value row is discarded, and another row is obtained from that input. T
- his process repeats until all rows have been processed by the engine.

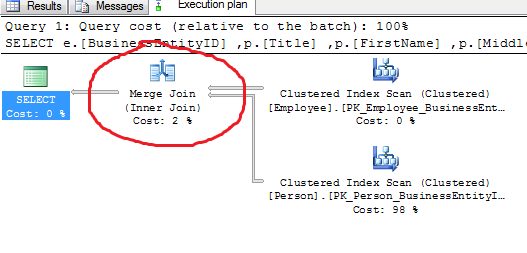
Merge Join
Hash Join:
The hash join can efficiently handle large, unsorted, and nonindexed inputs.
How it works:
- The hash join has two inputs: the build input and probe input with smaller input as build input.
- This type of join can be used for many types of set-based operations.
- Example;
- Inner join; left, right, and full outer join; left and right semi-join; intersection; union; and difference.
Types of hash join: It has below types;
- In-Memory Hash Join
- Grace Hash Join
- Recursive Hash Join
- Hash Bailout
In-Memory Hash Join
- This type of hash join first scans or computes the entire build input (small input) and then builds a hash table in memory.
- Each row is inserted into a hash bucket depending on the hash value computed for the hash key.
- If the entire build input is smaller than the available memory, all rows can be inserted into the hash table.
- This build phase is followed by the probe phase.
- The entire probe input is scanned or computed one row at a time, and for each probe row, the hash key's value is computed, the corresponding hash bucket is scanned, and the matches are produced.
Grace Hash Join
- In this type, if the build input does not fit in memory, a hash join proceeds in several steps.
- This is known as a grace hash join.
- Each step has a build phase and probe phase.
- Initially, the entire build and probe inputs are consumed and partitioned (using a hash function on the hash keys) into multiple files.
- Using the hash function on the hash keys guarantees that any two joining records must be in the same pair of files.
- Therefore, the task of joining two large inputs has been reduced to multiple, but smaller, instances of the same tasks.
- The hash join is then applied to each pair of partitioned files.
Recursive Hash Join
- In this type, if the build input is so large that inputs for a standard external merge would require multiple merge levels, multiple partitioning steps and multiple partitioning levels are required.
- If only some of the partitions are large, additional partitioning steps are used for only those specific partitions.
- In order to make all partitioning steps as fast as possible, large, asynchronous I/O operations are used so that a single thread can keep multiple disk drives busy.
Hash Bailout
The term hash bailout is sometimes used to describe grace hash joins or recursive hash joins.

{kind=link}
{kind=link}
{kind=link}
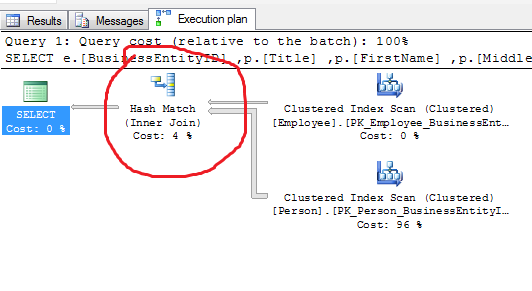
Hash Join
So, these are the internal joins known as physical joins used by SQL Server to perform any join.
Thanks for your reading and please share this post and rate it.
No comments:
Post a Comment